- August 30, 2024
- Posted by: Amala Mala Rajesh Samuel Dharshini
- Category: Informatica
Introduction:
Data Quality Rule Occurrence is used to run the DQ rule definition on the data elements. Rule Occurrence uses the data element as a Column. So, after the Rule Occurrence is created the DQ rule would directly run on the columns which are tagged as the primary data element and the secondary data elements.
Pre-requisites:
The following are the pre-requisites for the rule occurrence to be created and implemented.
- Table/View
- Catalog with data quality option enabled.
- Valid data quality rule specification.
Here, an employee table is used as a sample.

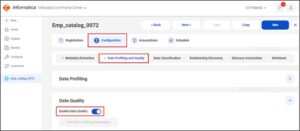
The sample catalog emp_catalog_0072, has the data quality option enabled under the configuration-> data profiling and Quality-> Enable Data Quality.
A valid rule specification is created in the data quality services.
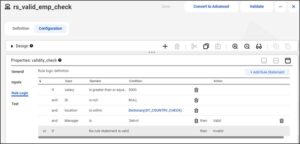
The rule states that the record is valid when salary is greater than equal to 5000 AND id is not null AND location is within the dictionary values, i.e, either India or London AND Manager name is ‘Selvin’.
Once the rule is valid, the rule occurrence can be created in the CDGC services.
Rule Occurrence Creation:
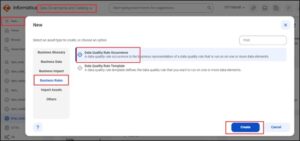
Switch to the Cloud Data Governance Catalog services to create the Rule Occurrence.
New -> Business Rules -> Data Quality Rule Occurrence -> Create.
Once the rule occurrence is created, fill in the required fields like Name, dimension, measuring method, primary data element.
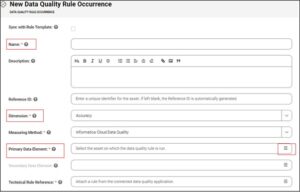
Name: Can be of the user choice.
Reference ID: Unique reference identifier to the rule occurrence. This an optional field, if you do not provide then the reference id will be auto generated.
Dimension: Can be based on the check that the user prefers to do like Accuracy, Validity, Completeness, Consistency, Uniqueness and Timeliness.
Measuring Method: Method by which the data quality rule for the rule occurrence is evaluated. These do not have any functionality behaviour. These are like tagging labels to the Rule Occurrence. By default, the DQ rules would be evaluated from the Informatica Cloud Data Quality. This field could have one of the following values: Business Extract, System Function, Technical Script, Informatica Cloud Data Quality.
Primary Data Element: Select the Primary Data Element which is a column on which you want to run the DQ rule definition.
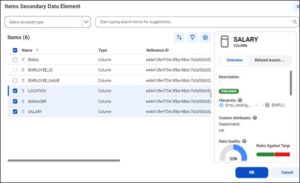
Secondary Data Element:
For the DQRO to be implemented for more than 1 column, the secondary data element must be selected. The remaining columns that are to be used for the DQ validation are mentioned in the secondary data element.
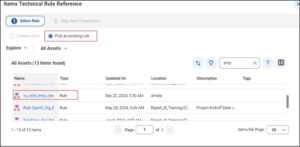
Pick the required valid rule specification from the technical rule reference and click next:
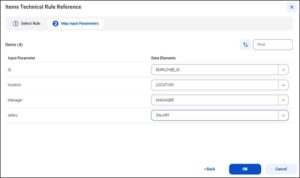
Now, map the respective input parameter with the data element and click ok.
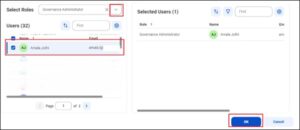
Assign the stack holders and click create.

The DQRO can be executed in two ways:
- Directly from the CDGC page by clicking run now option on the right top corner of the DQRO page.

2. Can be executed from the Metadata Command Centre through the catalog implemented.
Metadata Command Centre -> Explore-> Select the relevant Catalog-> Click Run-> Select the scope f run from the pop-up-> Click Run.
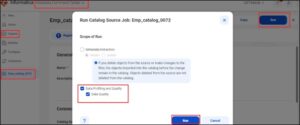
The score for the executed data quality rule occurrence for multiple columns on a single table is populated and can be viewed in the CDGC services.
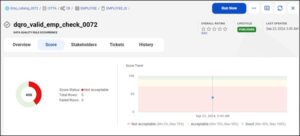
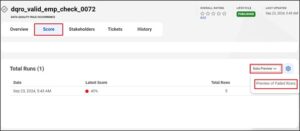
The score is generated based on the table values that satisfy the conditions mentioned in the rule specification. The rows that didn’t satisfy the conditions can be viewed in the preview of failed rows option.

Advantages of implementing Rule Occurrence on multiple columns of a table:
- Consistency: Keeps related data in different columns uniform, making it easier to trust.
- Integrity: Ensures that columns that should relate to each other do so correctly, preventing errors.
- Efficiency: Saves time by checking multiple columns at once instead of one by one.
- Thorough Checks: Allows for more complete checks of data, ensuring everything is validated together.
- Better Insights: Leads to more reliable data, which helps in making informed decisions.
- Simpler Maintenance: Makes it easier to update rules since they are centralized rather than scattered.
- Increased Trust: Builds confidence in the data’s accuracy, encouraging its use in decision-making.
- Compliance: Helps meet regulations by ensuring all necessary data is accurate and validated.
- Less Redundancy: Reduces duplicate checks for similar data, making the process more streamlined.
- Quick Error Detection: Helps identify problems early across multiple data points, allowing for faster fixes.
Limitations of implementing Rule Occurrence on multiple columns of a table:
- Complexity: It can get complicated to create and manage rules for many columns, making them hard to understand.
- Slower Performance: Checking multiple columns at once can slow down data processing, especially with large datasets.
- Interdependencies: If columns rely on each other in complicated ways, it’s tough to create accurate rules for them.
- False Alerts: Rules might incorrectly flag good data as bad (false positives) or miss errors (false negatives).
- Lack of Flexibility: A standard set of rules might not work well for all situations, limiting customization.
- Resource Heavy: Setting up and monitoring rules for many columns can take a lot of time and effort.
- Confusion from Overlap: Similar rules across columns can cause confusion and complicate data management.
- Harder Troubleshooting: Finding the source of a data issue can be trickier when multiple columns are involved.
- Need for User Training: Users may need extra training to understand and interpret the rules correctly.
- Dependence on Accurate Metadata: If the metadata is wrong, the rules may not work well, affecting data quality.
Conclusion:
Using data quality rule occurrence for multiple columns in a single table can greatly improve the accuracy and reliability of the data. This approach helps ensure that related data stays consistent and makes it easier to spot errors. However, it can also be complex and might slow down processing, so it’s important to manage these rules carefully. By finding the right balance, organizations can enjoy the benefits of high-quality data while keeping things manageable. Overall, this strategy supports better decisions and helps meet compliance requirements.
Please reach out to us for your Informatica solution needs. We are an Informatica Platinum Partner with extensive experience with Informatica implementations and data integration.